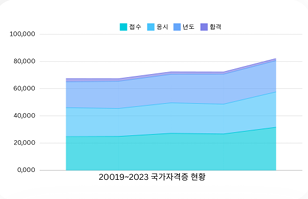
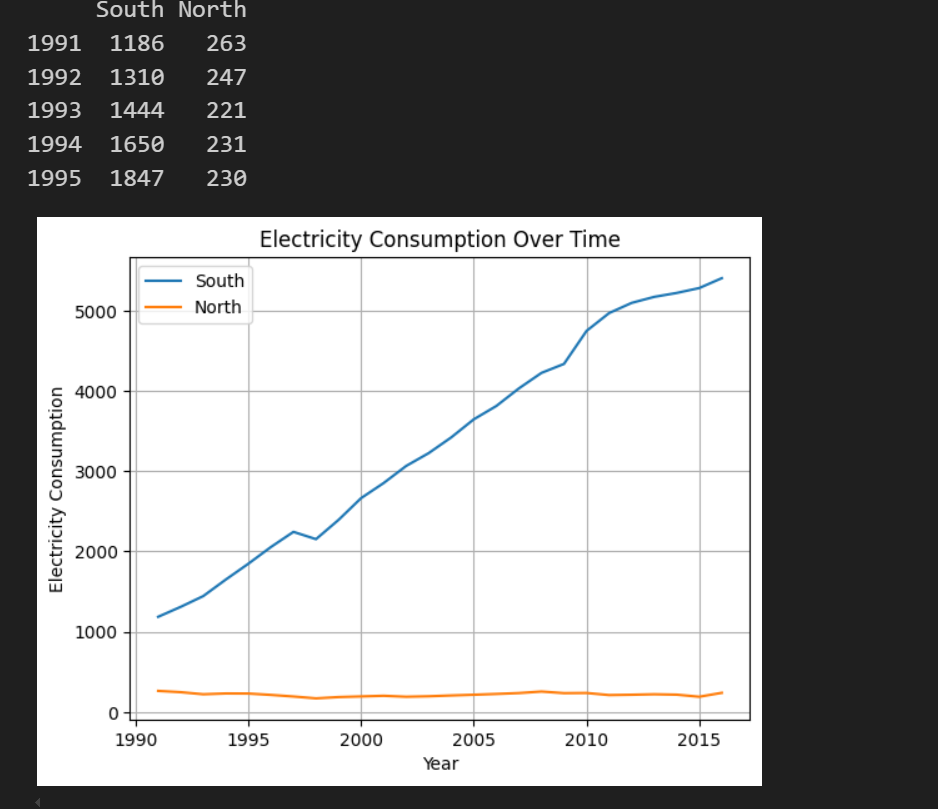
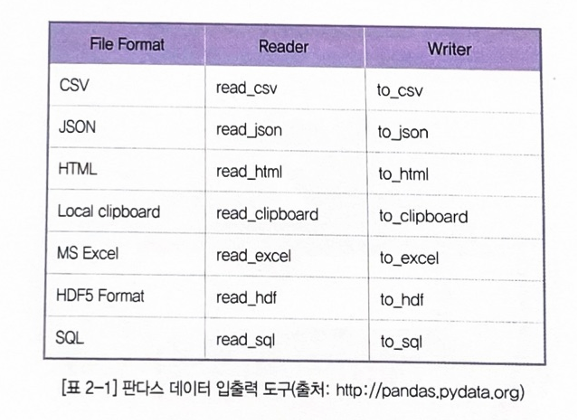
방학 스터디로 진행한 개인 프로젝트입니다. 약 3주정도 개인적으로 진행한 사이드프로젝트입니다. 1. 아이디어 배경보통 대부분의 대학교에는 따로 지정된 흡연장이 존재합니다. 거기에는 담배꽁초를 버릴 수 있는 쓰레기통과, 그런 쓰레기통의 청소를 담당하는 분이 따로 존재하여, 언제나 깨끗한 학교를 유지시켜줍니다. 하지만, 학교 밖을 나오자마자 상당히 많은 담배꽁초를 길거리에서 흔히 발견할 수 있습니다. 이는 대학교 근처에는 항상 있는 술집, 음식점, 카페 모두에 해당합니다. 환경미화원분들이 매일매일 길거리를 청소하지만, 매일 길거리에 버려지는 담배꽁초를 전부 담당하기는 역부족입니다. 저는 이런 길거리 담배꽁초, 길거리 흡연 등의 문제를 다른 흡연자 친구에게 물어보았더니, 지정 흡연장이 너무 멀거나, 없을때 길..