1. 누락 데이터 처리
- 누락 데이터 확인
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
print(df.head(10))
#실행시 이미 deck 열에 많은 NaN 값이 있는것을 확인
#얼마나 있는지 확인
nan_deck= df['deck'].value_counts(dropna=False) #dropna 값을 False로 해야지 nan 값을 카운트
print(nan_deck)
#결과
deck
NaN 688
C 59
B 47
D 33
E 32
A 15
F 13
G 4
Name: count, dtype: int64#누락 데이터를 찾는 직접적인 방법: isnull(), notnull() 메소드가 존재
isnull(): 누락된 데이터면 True를 반환
notnull(): 누락된 데이터면 False 반환
- 누락 데이터 제거
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
#for 반복문으로 각 열의 NaN 개수 계산
missing_df= df.isnull()
for col in missing_df.columns:
missing_count= missing_df[col].value_counts() #각 열의 NaN 개수 파악
try:
print(col, ': ', missing_count[True])
except:
print(col, ': ', 0)조회해보면 deck 의 데이터값이 688개가 누락된 것을 볼 수 있다. 매우 큰 수치이므로 데이터값이 존재하지 않는 행을 제거하는것보다는 deck 열 자체를 지우는게 현명하다.
droppa() 메소드에 thresh- 500 옵션을 설정하면 누락 값이 500개 이상인 열을 제거한다.
#NaN 값이 500개 이상인 열을 모두 삭제- deck열이 삭제
df_thresh= df.dropna(axis=1, thresh= 500)
print(df_thresh.columns)
#age 값 없는 행 제거하기
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
#age 누락 데이터행 제거
df_age= df.dropna(subset= ['age'], how= 'any', axis= 0)
print(len(df_age))dropna() 메소드에 subset을 age로 한정하면 age 의 열 중에서 NaN값이 있는 모든 행(axis=0)을 삭제.
기본값으로 how= any 옵션이 적용되는데, NaN 값이 하나라도 있으면 제거한다는 의미.
how= all 옵션은 모든 데이터가 NaN값일 때만 삭제
- 누락 데이터 치환
데이터의 품질을 올리기 위해서 누락된 데이터까지 쓴다. 이때 fillna() 메소드로 처리. 이때 원본 객체를 변경하기 위해서는 inplace= True 옵션을 추가해야 한다.
#평균으로 누락 데이터 바꾸기
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
#age 열의 NaN 값을 다른 나이 데이터의 평균으로 변경
mean_age= df['age'].mean(axis=0) #age열의 평군 계산(NaN값 제외)
df['age'].fillna(mean_age, inplace=True)
print(df['age'].head(10))#embark_town 열의 누락값을 가장 많이 나타나는 값으로 바꾸기
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
#embark_town 열의 NaN값을 승선도시 중에서 가장 많이 출현한 값 보이기
most_freq= df['embark_town'].value_counts(dropna=True).idxmax()
print(most_freq)
print('\n')
#embark_town 열의 Nan값을 가장 많이 나타나는 값으로 바꾸기
df['embark_town'].fillna(most_freq, inplace=True)#embark_town 열의 누락값을 바로 앞의 값으로 바꾸기
import seaborn as sns
#titanic dataset 불러오기
df = sns.load_dataset('titanic')
#embark_town 열의 NaN값을 바로 앞에 있는 값으로 대체하기
df['embark_town'].fillna(method='ffill', inplace=True)
2. 중복 데이터 처리
- 중복 데이터 확인
duplicated() 메소드를 활용하여 중복되는 행 레코드가 있는지 확인한다. 중복이라면 True를 반환한다
df_dup= df.duplicated() #데이터프레임 전체 행 데이터에서 중복값 찾기
col_dup= df['열'].duplicated() #데이터프레임의 특정 열 데이터에서 중복값 찾기
- 중복 데이터 제거
drop_duplicates() 메소드를 통해서 중복되는 행을 제거한다. 원본 객체를 수정하려면 마찬가지로 inplace= True로 설정
df2= df.drop_duplicates() #데이터프레임 전체에서 중복되는 행 찾아 제거
df3= df.drop_duplicates(subset= ['열1', '열2']) #두 열을 기준으로 중복되는 행 찾아 제거
3. 데이터 표준화
각각 데이터의 형태를 표준화시킨다
3-1 단위 환산
import pandas as pd
# read_csv() 함수로 df 생성
df = pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/auto-mpg.csv', header=None)
# 열 이름을 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
# mpg를 kpl로 변환(mpg_to_kpl = 0.425)
mpg_to_kpl = 1.60934/3.78541
# 새로운 열 추가
df['kpl'] = df['mpg'] * mpg_to_kpl
# 소수점 아래 둘째자리에서 반올림
df['kpl'] = df['kpl'].round(2)
print(df.head(3))
3-2 자료형 변환
#각 열의 자료형 확인을 통해서 각각의 열이 어떤 데이터타입을 가지고 있는지 확인
print(df.dtypes)
#horsepower 열의 고윳값 확인 -> 원래 숫자형이 어울리지만 값중 ? 값이 존재해 object로 나옴
#이럴때는 ? 값을 NaN값으로 만들고 NaN값을 삭제하는 dropna() 메소드를 사용
#누락 데이터('?') 삭제
import numpy as np
df['horsepower'].replace('?', np.nan, inplace=True) #'?'을 np.nan으로 변경
df.dropna(subset=['horsepower'], axis=0, inplace=True) #누락 데이터 행 삭제
df['horsepower'] = df['horsepower'].astype('float') #문자열을 실수형으로 변환
#horsepower 열의 자료형 확인
print(df['horsepower'].dtypes)#정수형 데이터를 문자형 데이터로 변환
df['origin'].replace({1:'USA', 2:'EU', 3:'JPN'}, inplace=True)#문자열을 범주형으로 변환
df['origin']= df['origin'].astype('category')
#범주형을 문자형으로 변환
df['origin']= df['origin'].astype('str')
4. 범주형(카테고리) 데이터 처리
4-1 구간 분할
연속 데이터를 일정한 구간(bin)으로 나눠서 구간별 차이를 드러낼 수 있다. 이처럼 연속 변수를 일정한 구간으로 나누고, 각 구간을 범주형 이산 변수로 변환하는 과정을 구간 분한(binning)이라고 한다. 판다스 cut() 함수를 이용하여 연속 데이터를 여러 구간으로 나누고 범주형 데이터로 변환할 수 있다.
경계값은 NumPy 라이브러리의 histogram() 함수를 이용하여 구할 수 있다. 나누려는 구간(bin) 개수를 bins 옵션에 입력하면 각 구간에 속하는 값의 개수(xount)와 경계값 리스트(bin_dividers)를 반환한다.

#데이터 구간 분할
import pandas as pd
# read_csv() 함수로 df 생성
df = pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/auto-mpg.csv', header=None)
# 열 이름을 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
#누락 데이터('?') 삭제하고 실수형으로 변환
import numpy as np
df['horsepower'].replace('?', np.nan, inplace=True) #'?'을 np.nan으로 변경
df.dropna(subset=['horsepower'], axis=0, inplace=True) #누락 데이터 행 삭제
df['horsepower'] = df['horsepower'].astype('float') #문자열을 실수형으로 변환
#np.histogram 함수로 3개의 bin으로 구분할 경계값의 리스트 구하기
count,bin_dividers= np.histogram(df['horsepower'], bins=3)
print(bin_dividers)#분할한 데이터에 cut()옵션을 통해서 각 구간이 이름을 할당
#3개의 bin 에 이름 지정
bin_names= ['저출력', '보통출력', '고출력']
#pd.cut 함수로 각 데이터를 3개의 bin에 할당
df['hp_bin']= pd.cut(x=df['horsepower'],
bins=bin_dividers #경계값 배열
labells=bin_names #경계값 리스트
include_lowest=True) #첫 경계값 포함
4-2 더미 변수
숫자 0,1로써 특정 특성을 가지는지 아닌지에 따라서 부여하는 더미 변수
get_dummies()함수를 사용헤 범주형 변수의 모든 고윳값을 각각 새로운 더미 변수로 변환
#hp_bin열의 범주형 데이터를 더미 변수로 변환
horsepower_dummies= pd.get_dummies(df['hp_bin'])
print(horsepower_dummies.head(15))sklearn 라이브러리를 이용하여 원핫인코딩을 편하게 처리할 수 있다.
범주형 데이터를 0,1을 원소로 갖는 원핫벡터로 변환한다
#sklern 라이브러리 불러오기
from sklearn import preprocessing
# 전처리를 위한 encoder 객체 만들기
label_encoder = preprocessing.LabelEncoder() # label encoder 생성
onehot_encoder = preprocessing.OneHotEncoder() # one hot encoder 생성
# label encoder로 문자열 범주를 숫자형 범주로 변환
onehot_labeled = label_encoder.fit_transform(df['hp_bin'].head(15))
print(onehot_labeled)
print(type(onehot_labeled))
# 2차원 행렬로 형태 변경
onehot_reshaped = onehot_labeled.reshape(len(onehot_labeled), 1)
print(onehot_reshaped)
print(type(onehot_reshaped))
# 희소행렬로 변환
onehot_fitted = onehot_encoder.fit_transform(onehot_reshaped)
print(onehot_fitted)
print(type(onehot_fitted))
5. 정규화
각 변수에 들어있는 숫자 데이터의 상대적 크기차이가 크면 머신러닝때 다른 결과가 나올 수 있음
정규화를 통해 각 데이터의 크기를 각각의 크기로 나눠 -1~1 사이값으로 만들기
#horsepower 열의 통계 요약 정보로 최대값(max) ghkrdls
print(df.horsepower.describe())
#horsepower 열의 최대값의 절대값으로 모든 데이터를 나눠서 저장
df.horspower= df.horsepower/abs(df.horsepower.max())#각 열의 데이터 중에서 최대값과 최소값을 뺀 값으로 나누기
min_x= df.horsepower - df.horsepower.min()
min_max= df.horsepower.max() - df.horsepower.min()
df.horsepower= min_x/min_max
6. 시계열 데이터
판다스의 시간 표시 방식 중에서 시계열 데이터 표현에 자주 이용되는 두 가지 유형
1. Timestamp
2. Period

6-1. 다른 자료형을 시계열 객체로 변환
대부분의 시간 데이터들은 시간 자료형이 아닌 문자열 또는 숫자로 저장되어 있음. 이걸 시간 자료형으로 변환하는 함수
Timestamp() 로 변환하기
- 문자열을 Timestampt로 변환
to_datetime()함수를 통해 문자열 등 다른 자료형을 판다스 Timestamp를 나타내는 자료형으로 변환 가능
import pandas as pd
#read_csv() 함수로 csv파일을 가져와 df로 변환
df= pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part5/data/stock-data.csv')
#데이터 내용 및 자료형 확인
print(df.head())
print('\n')
print(df.info())
#문자열 데이터(시리즈 객체)를 판다스 Timestamp로 변환
df['new_date'] = pd.to_datetime(df['date']) #df에 새로운 열로 추가이제 new_date 열을 추가했으니 기존에 있는 date열을 제거하고 해당 자리에 new_date행을 행 인덱스로 지정하면 된다.
import pandas as pd
#read_csv() 함수로 csv파일을 가져와 df로 변환
df= pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part5/data/stock-data.csv')
#문자열 데이터(시리즈 객체)를 판다스 Timestamp로 변환
df['new_date'] = pd.to_datetime(df['Date']) #df에 새로운 열로 추가
#시계열 값으로 변환된 열을 새로운 행 인덱스로 지정. 기존 날짜 열은 삭제
df.set_index('new_date', inplace=True)
df.drop('Date', axis=1, inplace=True)
#데이터 내용확인
print(df.head())
print('\n')
print(df.info())
- Timestamp를 Period로 변환
to_period() 함수를 이용하면 일정 기간을 나타내는 Period객체로 Timestamp객체를 변환할 수 있다.
import pandas as pd
#날짜 형식의 문자열로 구성되는 리스트 정의
dates= ['2019-01-01', '2020-03-01', '2021-06-01']
#문자열의 배열을 판ㄷ스 Timestamp로 변환
ts_dates= pd.to_datetime(dates)
print(ts_dates)
print('\n')
#Timestamp를 Period로 변환
pr_day= ts_dates.to_period(freq='D')
print(pr_day)
pr_month= ts_dates.to_period(freq='M')
print(pr_month)
pr_year= ts_dates.to_period(freq='A')
print(pr_year)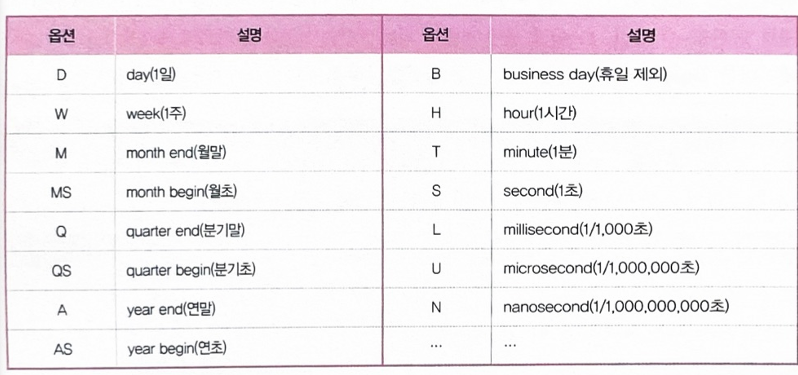
6-2 시계열 데이터 만들기
- Timestamp 배열
date_range() 함수를 사용하면 여러개의 날짜(Timestamp)가 들어 있는 배열 형태의 시계열 데이터를 만들 수 있다. 파이썬 range() 함수로 숫자 배열을 만드는 것과 유사하다.
# Timestamp의 배열 만들기 - 월 간격, 월의 시작일 기준
ts_ms = pd.date_range(start='2019-01-01', # 날짜 범위의 시작
end=None, # 날짜 범위의 끝
periods=6, # 생성할 Timestamp의 개수
freq='MS', # 시간 간격 (MS: 월의 시작일)
tz='Asia/Seoul') # 시간대(timezone)
# 분기(3개월) 간격, 월의 마지막 날 기준
ts_3m = pd.date_range('2019-01-01', periods=6,
freq='3M', # 시간 간격 (3M: 3개월)
tz='Asia/Seoul') # 시간대(timezone)
# 1번 출력 결과
DatetimeIndex(['2019-01-01 00:00:00+09:00', '2019-02-01 00:00:00+09:00',
'2019-03-01 00:00:00+09:00', '2019-04-01 00:00:00+09:00',
'2019-05-01 00:00:00+09:00', '2019-06-01 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Seoul]', freq='MS')
- period 배열
period_range() 함수는 여러 개의 기간(period)이 들어 있는 시계열 데이터를 만든다.
import pandas as pd
#Period 배열 만들기- 1개월 길이
pr_m= pd.period_range(start='2019-01-01', #날짜 범위시작
end= None, #날짜 범위 끝
periods=3, #생성할 period 개수
freq='M') #기간의 길이
print(pr_m)기간의 길이 freq= 'H' 로 놓음으로써 날짜 범위 시작부터 period의 수에 따라서 1시간마다 자르는 것도 가능
2H면 2시간 간격임
6-3 시계열 데이터 활용
- 날짜 데이터 분리
연-월-일 날짜 데이터에서 일부를 분리하여 추출할 수 있다.
import pandas as pd
df = pd.read_csv('stock-data.csv')
# 문자열인 날짜 데이터를 판다스 Timestamp로 변환
df['new_Date'] = pd.to_datetime(df['Date']) #df에 새로운 열로 추가
# dt 속성을 이용하여 new_Date 열의 년월일 정보를 년, 월, 일로 구분
df['Year'] = df['new_Date'].dt.year
df['Month'] = df['new_Date'].dt.month
df['Day'] = df['new_Date'].dt.day
# Timestamp를 Period로 변환하여 년월일 표기 변경하기
df['Date_yr'] = df['new_Date'].dt.to_period(freq='A')
df['Date_m'] = df['new_Date'].dt.to_period(freq='M')
# 원하는 열을 새로운 행 인덱스로 지정
df.set_index('Date_m', inplace=True)
- 날짜 인덱스 활용
import pandas as pd
df = pd.read_csv('stock-data.csv')
# 문자열인 날짜 데이터를 판다스 Timestamp로 변환
df['new_Date'] = pd.to_datetime(df['Date']) # 새로운 열에 추가
df.set_index('new_Date', inplace=True) # 행 인덱스로 지정
# 날짜 인덱스를 이용하여 데이터 선택하기
df_y = df['2018']
df_ym = df.loc['2018-07'] # loc 인덱서 활용
df_ym_cols = df.loc['2018-07', 'Start':'High'] # 열 범위 슬라이싱
df_ymd = df['2018-07-02']
df_ymd_range = df['2018-06-25':'2018-06-20'] # 날짜 범위 지정
# 시간 간격 계산. 최근 180일 ~ 189일 사이의 값들만 선택하기
today = pd.to_datetime('2018-12-25') # 기준일 생성
df['time_delta'] = today - df.index # 날짜 차이 계산
df.set_index('time_delta', inplace=True) # 행 인덱스로 지정
df_180 = df['180 days':'189 days']'파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 4주차- 머신러닝 데이터분석 (0) | 2024.08.25 |
|---|---|
| 4주차- 데이터프레임의 다양한 응용 (0) | 2024.08.22 |
| 3주차-시각화 도구 및 데이터 사전 처리 (0) | 2024.08.21 |
| 2주차- 데이터 살펴보기 (0) | 2024.08.14 |
| 2주차- 데이터 입출력 (0) | 2024.08.14 |