3주차-시각화 도구 및 데이터 사전 처리
4. 시각화 도구
데이터를 모았고, 형태를 구분했으면 이제는 데이터를 시각화를 통해서 데이터가 주는 인사이트를 알아야 한다.
다양한 동구를 통해서 데이터시각화가 가능하며 시각화를 하려면 데이터를 정제해야한다.
4-1. Matplotlib - 기본 그래프 도구
1-1. 선 그래프
선 그래프는 연속하는 데이터값들을 직선 또는 곡선으로 연결하여 데이터 값 사이의 관계를 나타낸다. 특히 시계열 데이터와 같이 연속적인 값의 변화화 패턴을 파악하는데 적합하다.
#예제 4-1 선 그래프
import pandas as pd
import matplotlib.pyplot as plt
#엑셀 데이터를 데이터프레임으로 변환
df = pd.read_excel('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/시도별_전출입_인구수.xlsx', engine='openpyxl', header=0)
#누락 값을 앞 데이터로 채우기(엑셀 셀 병합되어있는 데이터 사용할때 이런식으로 함)
df = df.fillna(method='ffill')
#서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
#전출지별에서 서울특별시 라는 값을 갖는 데이터만 추출하여 df_seoul 로 저장하고 전입지별의 이름을 전입지로 바꾸고 전입지 열을 df_seoul의 행 인덱스로 지정
mask = (df['전출지별'] =='서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace= True)
df_seoul.set_index('전입지', inplace=True)
#전입지가 경기도 인 행 데이터를 선택하여 sr_one에 저장. 서울에서 경기도로 이동한 인구 데이터를 나타낼 수 있음
sr_one = df_seoul.loc['경기도']
#x,y 축 데이터를 plot 함수에 입력
plt.plot(sr_one.index, sr_one.values)
- 차트 제목, 축 이름 추가하는 법
#차트 제목 추가
plt.title('서울 -> 경기 인구이동')
#축 이름 추가
plt.xlabel('기간')
plt.ylabel('이동 인구수')
- Matplotlib 한글 폰트 오류 해결
#Mataplotlib 한글 폰트 오류 해결
from mataplotlib import font_manager, rc
font_path = "/폰트파일위치"
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family= font_name)
- 그래프 꾸미기
x축 눈금 라벨의 글씨가 서로 겹쳐서 보이지 않는 문제 해결하기. 그림사이즈를 조정해 x축에 여유를 준다
plt.figure(figsize=(14,5)) #그림 사이즈 조정(가로 14인치, 세로 5인치)
plt.xticks(rotation='vertical') #축 눈금 라벨 회전하기
plt.legend(labels=['서울 -> 경기'], loc= 'best') #범례 표시

- Mataplotlib의 스타일 서식 지정
같은 선 차트라도 다양한 스타일이 있음
import mataplotlib.pyplot as plt
#스타일 리스트 출력
print(plt.style.available)# ggplot 스타일 서식 지정
plt.style.use('ggplot')
# x축 눈금 라벨 폰트크기 10, 회전
plt.xticks(size=10, rotation='vertical')
# plot() 함수에 marker='o' 옵션을 추가하여 점을 마커로 표현, markersize=10으로 사이즈 조절
plt.plot(sr_one.index, sr_one.values, marker='o', markersize=15)
공부하던 도중 차트가 2개가 나오고, 앞에 추가하는 변동사항이 2번째의 그래프에만 추가되는 현상 발생. gpt에게 물어봄
"
차트가 두 개 나오는 이유는 plt.plot과 plt.figure가 연속으로 호출되었기 때문입니다. 첫 번째 plt.plot 호출이 그래프를 생성하고, 그 다음에 plt.figure가 새로운 빈 그림을 만들어서 차트가 두 번 생성되는 문제가 발생합니다.
이 문제를 해결하려면, plt.figure를 먼저 호출하여 그림을 설정한 후, plt.plot을 호출하여 데이터를 그리도록 수정해야 합니다.
"
요렇게 나온다. 즉 plot과 figure 의 순서적 차이로 인해서 plot함수로 인한 차트가 생성되고 거기에 데이터프레임이 들어간다. 그리고 나서 figure함수로 인한 차트가 생성되고, 여태 했던 변경사항이 거기에 저장되는 것이다!
#즉 요놈의 위치가 문제였다
# 이동 인구 데이터 plot
plt.plot(sr_one.index, sr_one.values, label='서울 -> 경기')
#이놈의 위치를 figure 아래로 내리니까 해결됬다
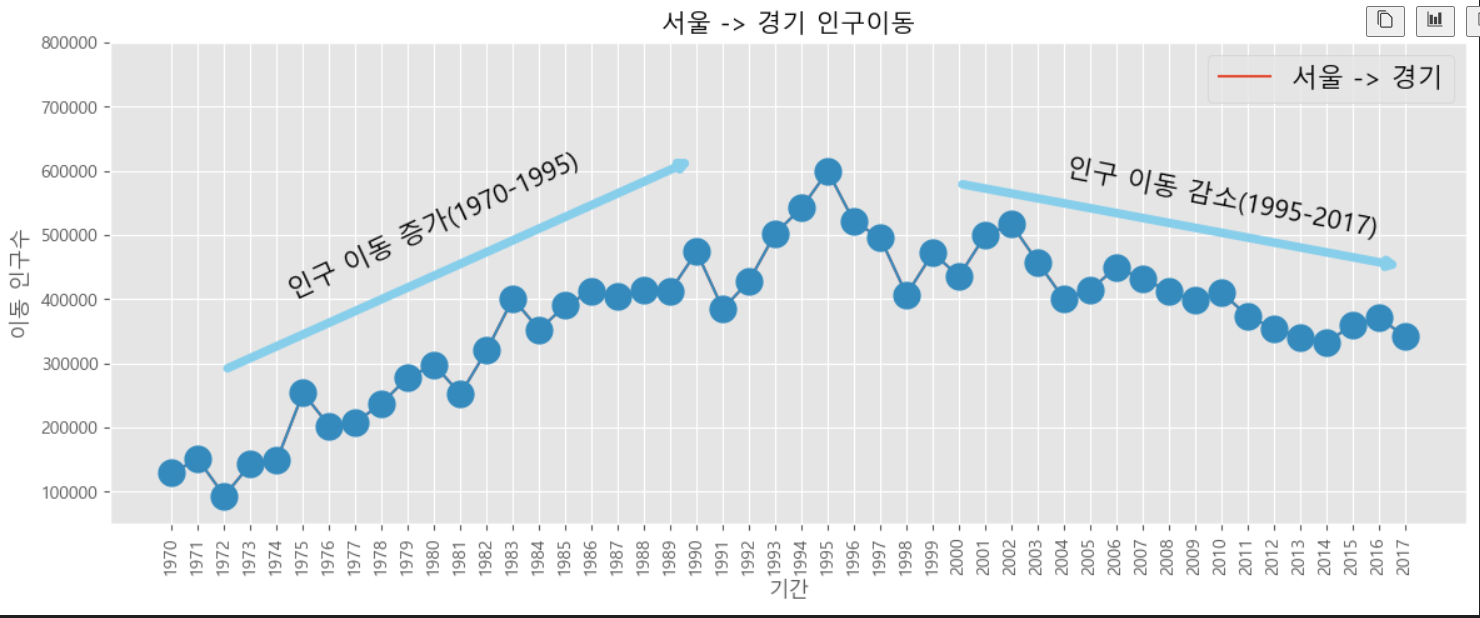
- 그래프에 주석 추가하기
annotate() 함수를 이용하여 그래프에 주석을 추가한다.
annotate() 함수의 옵션:
1. arrowprops: 사용하면 텍스트 대신 화살표가 표시된다. 이때 화살표 스타일, 시작점과 끝점의 좌표를 입력한다.
2. (x,y) 좌표: 위치를 나타내는 값으로, x값은 인덱스 번호를, y값은 데이터 숫자값으로 사용한다. xy=(20,620000)은 인덱스 20을 x값으로 하고 620,000명을 y값으로 한다는 뜻이다.
3. rotation 옵션: 양(+)의 회전 방향은 반시계방향
4. va: 'center', 'top', 'bottom', 'baseline'
5. ha: 'center, ' left', 'right'
# y축 범위 지정 (최소값, 최대값)
plt.ylim(50000,800000)
# 주석 표시 - 화살표
plt.annotate('',
xy = (20,620000), # 화살표의 머리 부분(끝점)
xytext=(2,290000), # 화살표의 꼬리 부분(시작점)
xycoords='data', # 좌표체계
arrowprops=dict(arrowstyle='->', color='skyblue', lw=5) # 화살표 서식
)
# 주석 표시 - 화살표
plt.annotate('',
xy = (47,450000), # 화살표의 머리 부분(끝점)
xytext=(30,580000), # 화살표의 꼬리 부분(시작점)
xycoords='data', # 좌표체계
arrowprops=dict(arrowstyle='->', color='skyblue', lw=5) # 화살표 서식
)
# 주석 표시 - 텍스트
plt.annotate('인구 이동 증가(1970-1995)', #텍스트 입력
xy = (10,400000), # 텍스트 위치 기준점
rotation=25, # 텍스트 회전 각도
va='baseline', # 텍스트 상하 정렬
ha='center', # 텍스트 좌우 정렬
fontsize=15, # 텍스트 크기
)
# 주석 표시 - 텍스트
plt.annotate('인구 이동 감소(1995-2017)', #텍스트 입력
xy = (40,500000), # 텍스트 위치 기준점
rotation=-11, # 텍스트 회전 각도
va='baseline', # 텍스트 상하 정렬
ha='center', # 텍스트 좌우 정렬
fontsize=15, # 텍스트 크기
)
- 화면 분할하기- axe 객체 사용
화면을 여러 개로 분할하고 분할된 각 화면에 서로 다른 그래프를 그리는 방법. 여러 개의 axe 객체를 만들고, 분할된 화면마다 axe 객체를 하나씩 배정한다.
1. figure() 함수를 이용해서 그래프를 그리는 그림틀(fig)를 만든다.
2. fig 객체에 add_subplot()메소드를 적용하여 그림틀을 여러개로 분할한다. 이때 각 나눠진 부분을 axe 객체라 한다.
3. add_subplot() 메소드의 인자에 "행크기, 열크기, 서브플롯 순서" 순으로 입력
4. 그 후, 각 axe 객체에 plot 메소드를 적용하여 그래프를 출력
# 그래프 객체 생성
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
# axe 객체에 plot 함수로 그래프 출력
ax1.plot(sr_one,'o', markersize=10) # 선을 그리지 않고 점으로만
ax2.plot(sr_one, marker='o', markerfacecolor='green', markersize=10, color='olive',linewidth=2,label='서울->경기')
ax2.legend(loc='best') # 범례 표시
# y축 범위 지정
ax1.set_ylim(50000,800000)
ax2.set_ylim(50000,800000)
# 축 눈금 라벨 지정 및 75도 회전
ax1.set_xticklabels(sr_one.index,rotation=75)
ax2.set_xticklabels(sr_one.index,rotation=75)

- 분할된 그래프에 제목과 축 이름 추가하기
# 그래프 객체 생성
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(1,1,1)
# 차트 제목 추가
ax.set_title('서울 -> 경기 인구 이동', size=20)
# 축 이름 추가
ax.set_xlabel('기간', size=12)
ax.set_ylabel('이동 인구수', size=12)
# 축 눈금 라벨 지정 및 75도 회전
ax.set_xticklabels(sr_one.index,rotation=75)
# 축 눈금 라벨 크기
ax.tick_params(axis="x", labelsize=10)
ax.tick_params(axis="y", labelsize=10)- 동일 그림에 여러개의 그래프 추가하기
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 한글 폰트 설정
font_path = "C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
# 엑셀 데이터를 데이터프레임으로 변환
df = pd.read_excel('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/시도별_전출입_인구수.xlsx', engine='openpyxl', header=0)
# 누락 값을 앞 데이터로 채우기
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별': '전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 충남, 경북, 강원도로 이동한 인구 데이터 3개의 값 선택
col_years = list(map(str, range(1970, 2018)))
df_3 = df_seoul.loc[['충청남도', '경상북도', '강원도'], col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig = plt.figure(figsize=(20, 5))
ax = fig.add_subplot(1, 1, 1)
# axe 객체에 plot 함수로 그래프 출력
ax.plot(col_years, df_3.loc['충청남도', :], marker='o', markerfacecolor='green',
markersize=10, color='olive', linewidth=2, label='서울 -> 충남')
ax.plot(col_years, df_3.loc['경상북도', :], marker='o', markerfacecolor='blue',
markersize=10, color='skyblue', linewidth=2, label='서울 -> 경북')
ax.plot(col_years, df_3.loc['강원도', :], marker='o', markerfacecolor='red',
markersize=10, color='magenta', linewidth=2, label='서울 -> 강원')
# 범례 표시
ax.legend(loc='best')
# 차트 제목 추가
ax.set_title('서울 -> 충남, 경북, 강원 인구 이동', size=20)
# 축 이름 추가
ax.set_xlabel('기간', size=12)
ax.set_ylabel('이동 인구수', size=12)
# 축 눈금 라벨 지정 및 90도 회전
ax.set_xticks(range(len(col_years))) # x축 위치
ax.set_xticklabels(col_years, rotation=90) # 라벨 설정 및 회전
# 축 눈금 라벨 크기
ax.tick_params(axis="x", labelsize=10)
ax.tick_params(axis="y", labelsize=10)
plt.show()
- 화면을 분할하여 다른 데이터 시각화
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 한글 폰트 설정
font_path = "C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
# 엑셀 데이터를 데이터프레임으로 변환
df = pd.read_excel('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/시도별_전출입_인구수.xlsx', engine='openpyxl', header=0)
# 누락 값을 앞 데이터로 채우기
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별': '전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 충남, 경북, 강원도로 이동한 인구 데이터 3개의 값 선택
col_years = list(map(str, range(1970, 2018)))
df_4 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig = plt.figure(figsize=(20, 5))
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
# axe 객체에 plot 함수로 그래프 출력
ax1.plot(col_years, df_4.loc['충청남도', :], marker='o', markerfacecolor='green',
markersize=10, color='olive', linewidth=2, label='서울 -> 충남')
ax2.plot(col_years, df_4.loc['경상북도', :], marker='o', markerfacecolor='blue',
markersize=10, color='skyblue', linewidth=2, label='서울 -> 경북')
ax3.plot(col_years, df_4.loc['강원도', :], marker='o', markerfacecolor='red',
markersize=10, color='magenta', linewidth=2, label='서울 -> 강원')
ax4.plot(col_years, df_4.loc['전라남도', :], marker='o', markerfacecolor='orange',
markersize=10, color='yellow', linewidth=2, label='서울 -> 전남')
# 범례 표시
ax1.legend(loc='best')
ax2.legend(loc='best')
ax3.legend(loc='best')
ax4.legend(loc='best')
# 차트 제목 추가
ax1.set_title('서울 -> 충남 인구 이동', size=15)
ax2.set_title('서울 -> 경북 인구 이동', size=15)
ax3.set_title('서울 -> 강원 인구 이동', size=15)
ax4.set_title('서울 -> 전남 인구 이동', size=15)
# 축 이름 추가, 90도 회전
ax1.set_xticklabels(col_years,rotation=90)
ax2.set_xticklabels(col_years,rotation=90)
ax3.set_xticklabels(col_years,rotation=90)
ax4.set_xticklabels(col_years,rotation=90)
plt.show()
1-2 면적 그래프
면적 그래프는 각 열의 데이터를 선 그래프로 구현한느데, 선 그래프와 x축 사이의 공간에 색이 입혀진다. 선 그래프를 그리는 plot() 메소드에 kind = 'area' 옵션을 선택하여 간단하게 그릴 수 있다.
그래프를 누적할지의 여부는 stacked=True 옵션을 통해 설정 가능하다.
- stacked =false 그래프
# 서울에서 충남, 경북, 강원도로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(1970,2018)))
df_4=df_seoul.loc[['충청남도','경상북도','강원도'],col_years]
df_4=df_4.T
# 스타일 서식 지정
plt.style.use('ggplot')
# 데이터프레임의 인덱스를 정수형으로 변경(x축 눈금 라벨 표시)
df_4.index = df_4.index.map(int)
# 면적 그래프 그리기
df_4.plot(kind='area', stacked=False, alpha=0.2, figsize=(20,10))
plt.title('서울 -> 타시도 인구 이동', size=30)
plt.xlabel('이동 인구 수', size=20)
plt.ylabel('기간', size=20)
plt.legend(loc='best', fontsize=15)
- stacked=true 그래프
# 면적 그래프 그리기
df_4.plot(kind='area', stacked=True, alpha=0.2, figsize=(20,10))
- axes 객체 속성 변경하기
axe 객체의 속성을 이용하여 제목, 축 이름 등을 설정한다
# 면적 그래프 그리기
ax = df_4.plot(kind='area', stacked=True, alpha=0.2, figsize=(20,10))
print(type(ax))
# axe 객체 설정 변경
ax.set_title('서울 -> 타시도 인구 이동', size=30, color='brown', weight='bold')
ax.set_xlabel('이동 인구 수', size=20)
ax.set_ylabel('기간', size=20)
ax.legend(loc='best', fontsize=15)
>> <class 'matplotlib.axes._axes.Axes'>
1-3 막대 그래프
plot() 메소드에 kind='bar' 옵션을 통해 막대 그래프를 설정한다.
- 세로형 막대 그래프
# 서울에서 충남, 경북, 강원도로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(2010,2018)))
df_4=df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
df_4=df_4.T
# 스타일 서식 지정
plt.style.use('ggplot')
# 데이터프레임의 인덱스를 정수형으로 변경(x축 눈금 라벨 표시)
df_4.index = df_4.index.map(int)
# 막대 그래프 그리기
ax = df_4.plot(kind='bar', figsize=(20,10), width=0.7, #kind='bar' 입력
color=['orange','green','skyblue','blue'])
# axe 객체 설정 변경
plt.title('서울 -> 타시도 인구 이동', size=30, color='brown', weight='bold')
plt.xlabel('이동 인구 수', size=20)
plt.ylabel('기간', size=20)
plt.ylim(5000,30000)
ax.legend(loc='best', fontsize=15)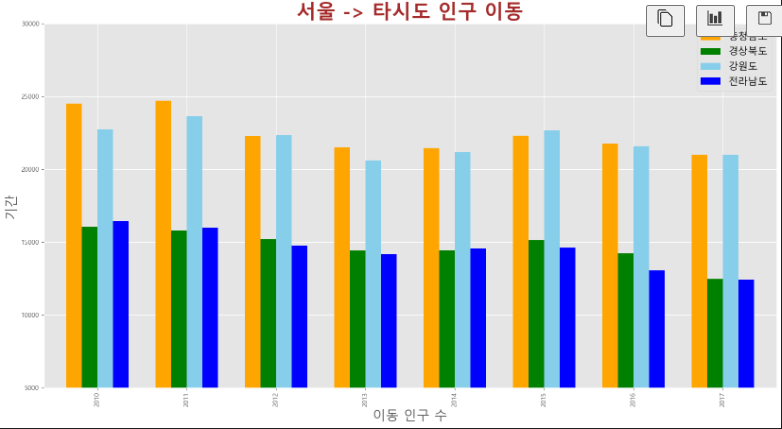
- 가로형 막대 그래프
# 서울에서 충남, 경북, 강원도로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(2010,2018)))
df_4=df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
#인구 수를 합계하여 새로운 열로 추가
df_4['합계'] = df_4.sum(axis=1)
# 가장 큰 값부터 정렬
df_total = df_4[['합계']].sort_values(by='합계', ascending=True)
# 스타일 서식 지정
plt.style.use('ggplot')
df_total.plot(kind='barh', color='cornflowerblue', width=0.5, figsize=(10,5)) #kind= 'barh'
# axe 객체 설정 변경
plt.title('서울 -> 타시도 인구 이동', size=20, color='brown', weight='bold')
plt.xlabel('이동 인구 수', size=20)
plt.ylabel('전입지', size=20)
1-4 히스토그램
plot() 메소드에 kind='hist' 옵션을 통해 히스토그램을 설정한다.
import pandas as pd
import matplotlib.pyplot as plt
# 스타일 서식 지정
plt.style.use('classic')
df = pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/auto-mpg.csv', header=None)
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
# 연비(mpg) 열에 대한 히스토그램 그리기
df['mpg'].plot(kind='hist', bins=10,color='coral',figsize=(10,5))
plt.title('Histogram')
plt.xlabel('mpg')
plt.show()
1-5 산점도
plot() 메소드에 kind='scatter' 옵션을 통해 산점도를 설정한다. 보통 산점도는 xy그래프 에서 점의 분포를 통해서 관계를 확인한다.
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('default') # 스타일 서식 지정
# read_csv() 함수로 df 생성
df = pd.read_csv('./part4/auto-mpg.csv', header=None)
# 열 이름을 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
# 연비(mpg)와 차중(weight) 열에 대한 산점도 그리기 - 점 색상과 크기 설정
df.plot(kind='scatter', x='weight', y='mpg', c='coral', s=10, figsize=(10, 5))
plt.title('Scatter Plot - mpg vs. weight')
plt.show()
# cylinders 개수의 상대적 비율을 계산하여 시리즈 생성
cylinders_size = df.cylinders / df.cylinders.max() * 300
# 3개의 변수로 산점도 그리기
df.plot(kind='scatter', x='weight', y='mpg', c='coral', figsize=(10, 5),
s=cylinders_size, alpha=0.3)
plt.title('Scatter Plot: mpg-weight-cylinders')
plt.show()
1-6 파이 차트
plot() 메소드에 kind='scatter' 옵션을 통해 산점도를 설정한다.
# 데이터 개수 카운트를 위해 값 1을 가진 열 추가
df['count'] = 1
df_origin = df.groupby('origin').sum()
# 제조국가(origin) 값을 실제 지역명으로 변경
df_origin.index = ['USA','EU','JPN']
# 파이차트 그리기
df_origin['count'].plot(kind='pie',
figsize=(7,5),
autopct='%1.1f%%', # 숫자를 소수점 이하 첫째자리까지 퍼센트로 표시
startangle=10, # 파이 조각을 나누는 시작점(각도 표시)
colors=['chocolate','bisque','cadetblue']
)
plt.legend(labels=df_origin.index, loc='upper right')
plt.show()
1-7 박스플롯
# 제조국가별 연비 분포
import pandas as pd
import matplotlib.pyplot as plt
# 한글 폰트
from matplotlib import font_manager, rc
font_path = "C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font',family=font_name)
plt.style.use('default') #스타일 서식 지정
plt.rcParams['axes.unicode_minus']=False # 마이너스 부호 출력 설정
df = pd.read_csv('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/auto-mpg.csv', header=None)
df.columns=['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
# 그래프 객체 생성 (figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.boxplot(x=[df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels=['USA','EU','JAPAN'])
ax2.boxplot(x=[df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels=['USA','EU','JAPAN'],
vert=False) # 수평 박스 플롯
plt.show()

4.2 Seaborn 라이브러리 - 고급 그래프 도구
- 데이터셋 가져오기
import seaborn as sns
titanic = sns.load_dataset('titanic')- 회귀선이 있는 산점도
regplot() 함수는 서로다른 2개의 연속변수 사이의 산점도를 그리고 선형회기분석이 의한 회기선을 함께 나타냄
fit_reg=False 옵션을 통해 회기선을 안 보이게 할 수 있다.
import matplotlib.pyplot as plt
import seaborn as sns
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정 (5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set_style('darkgrid')
# 그래프 객체 생성 (figure에 2개의 서브 플롯을 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 그래프 그리기 - 선형회귀선 표시(fit_reg=True)
sns.regplot(x='age', #x축 변수
y='fare', #y축 변수
data=titanic, #데이터
ax=ax1) #axe 객체 - 1번째 그래프
# 그래프 그리기 - 선형회귀선 미표시(fit_reg=False)
sns.regplot(x='age', #x축 변수
y='fare', #y축 변수
data=titanic, #데이터
ax=ax2, #axe 객체 - 2번째 그래프
fit_reg=False) #회귀선 미표시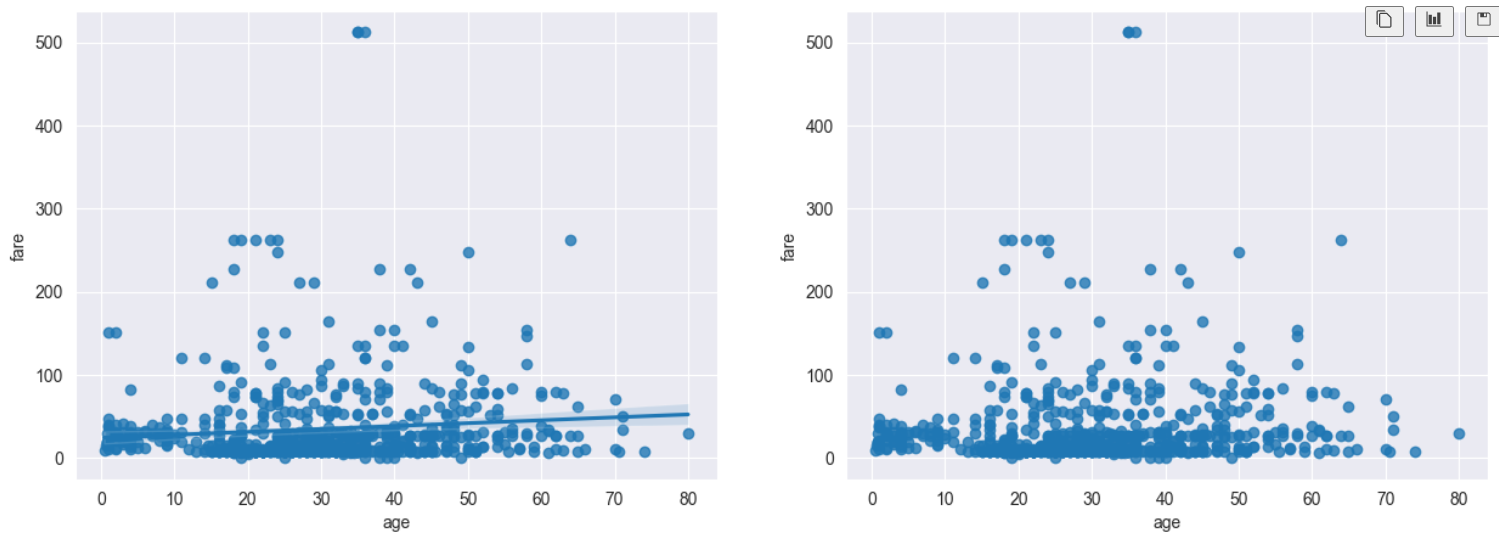
- 히스토그램/커널 밀도 그래프
단변수 데이터의 분포를 확인할 때 displot() 함수를 이용한다. 기본값으로 히스토그램과 커널 밀도 함수를 그래프로 출력
# 그래프 객체 생성 (figure에 3개의 서브 플롯을 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
# distplot
sns.distplot(titanic['fare'], ax=ax1)
# kdeplot
sns.kdeplot(x='fare', data=titanic, ax=ax2)
# histplot
sns.histplot(x='fare', data=titanic, ax=ax3)
# 차트 제목 표시
ax1.set_title('titanic fare - distplot')
ax2.set_title('titanic fare - kedplot')
ax3.set_title('titanic fare - histplot')
- 히트맵
seaborn 라이브러리는 히트맵을 그리는 heatmap() 메소드를 제공한다. 2개의 번주형 변수를 각각 x,y축에 놓고 데이터를 매트릭스 형태로 분류한다. 데이터프레임을 피벗테이블로 정리할 때 변수를 행 인덱스로 나머지 변수를 열 이름으로 설정한다.
aggfunc='size' 옵션은 데이터의 값의 크기를 기준으로 집계한다.
cbar = True를 하면 컬러 바를 사용
# 피벗테이블로 범주형 변수를 각각 행, 열로 재구분하여 정리
table = titanic.pivot_table(index=['sex'], columns=['class'], aggfunc='size')
# aggfunc = 'size' 옵션은 데이터 값의 크기를 기준으로 집계한다는 뜻
# 히트맵 그리기
sns.heatmap(table, # 데이터프레임
annot=True, fmt='d', # 데이터 값 표시 여부, 정수형 포맷
cmap='YlGnBu', # 컬러 맵
linewidth=.5, # 구분 선
cbar=False) # 컬러 바 표시 여부
- 범주형 데이터의 산점도
범주형 변수에 들아 있는 각 범주별 데이터의 분포를 확인하는 방법이다. stripplot() 함수와 swamplot() 함수를 사용할 수 있다. swarmplot() 함수는 데이터의 분산까지 고려하여, 데이터 포인트가 서로 중복되지 않도록 그린다.
# 그래프 객체 생성 (figure에 2개의 서브 플롯을 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 이산형 변수의 분포 - 데이터 분산 미고려
sns.stripplot(x="class", #x축 변수
y="age", #y축 변수
data=titanic, #데이터셋 - 데이터프레임
ax=ax1) #axe 객체 - 1번째 그래프
# 이산형 변수의 분포 - 데이터 분산 고려 (중복 X)
sns.swarmplot(x="class", #x축 변수
y="age", #y축 변수
data=titanic, #데이터셋 - 데이터프레임
ax=ax2) #axe 객체 - 2번째 그래프
# 차트 제목 표시
ax1.set_title('Strip Plot')
ax2.set_title('Strip Plot')
# hue='sex' 옵션을 함수에 추가하면 남녀 성별을 색상으로 구분하여 출력함
- 막대 그래프
막대 그래프는 barplot() 함수를 통해 사용한다.
# 그래프 객체 생성 (figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
#x축, y축에 변수 할당
sns.barplot(x= 'sex', y='survived', data=titanic, ax=ax1)
#x축, y축에 변수 할당하고 hue 옵션 추가
sns.barplot(x='sex', y='survived', hue='class', data=titanic, ax=ax2)
#x축, y축에 변수 할당하고 hue 옵션 추가하여 누적 출력
sns.barplot(x='sex', y='survived', hue='class',dodge= False, data=titanic, ax=ax3)
#차트 제목 표시
ax1.set_title('titanic survived - sex')
ax2.set_title('titanic survived - sex/class')
ax3.set_title('titanic survived - sex/class(stacked)')
- 빈도 그래프
각 범주에 속하는 데이터의 개수를 막대 그래프로 나타낸다. 함수는 countplol()을 사용한다
import matplotlib.pyplot as plt
import seaborn as sns
# Seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정
sns.set_style('whitegrid')
#figure에 3개의 서브 플롯 생성
fig2 = plt.figure(figsize=(15, 5))
ax4 = fig2.add_subplot(1, 3, 1)
ax5 = fig2.add_subplot(1, 3, 2)
ax6 = fig2.add_subplot(1, 3, 3)
# 기본값
sns.countplot(x='class', palette='Set1', data=titanic, ax=ax4)
# hue 옵션에 'who' 추가
sns.countplot(x='class', hue='who', palette='Set2', data=titanic, ax=ax5)
# dodge=False 옵션 추가 (축 방향으로 분리하지 않고 누적 그래프 출력)
sns.countplot(x='class', hue='who', palette='Set3', dodge=False, data=titanic, ax=ax6)
# 차트 제목 표시
ax4.set_title('titanic class')
ax5.set_title('titanic class - who')
ax6.set_title('titanic class - who (stacked)')
plt.show()
- 박스플롯- 바이올린 그래프
#figure에 3개의 서브 플롯 생성
fig2 = plt.figure(figsize=(15, 10))
ax1 = fig2.add_subplot(2, 2, 1)
ax2 = fig2.add_subplot(2, 2, 2)
ax3 = fig2.add_subplot(2, 2, 3)
ax4 = fig2.add_subplot(2, 2, 4)
# 박스 그래프 - 기본값
sns.boxplot(x='alive', y='age', data=titanic, ax=ax1)
# 바이올린 그래프 - hue 변수 추가
sns.boxplot(x='alive', y='age', hue='sex', data=titanic, ax=ax2)
# 박스 그래프 - 기본값
sns.violinplot(x='alive', y='age', data=titanic, ax=ax3)
# 바이올린 그래프 - hue 변수 추가
sns.violinplot(x='alive', y='age', hue='sex', data=titanic, ax=ax4)
- 조인트 그래프
산점도를 기본으로 표시하고 x-y축에 각 변수에 대한 히스토그램을 동시에 보여준다. 따라서 두 변수의 관계와 데이터가 분산되어 있는 정도를 한눈에 파악하기 좋다.
# 조인트 그래프 - 산점도(기본값)
j1 = sns.jointplot(x='fare', y='age', data=titanic)
# 조인트 그래프 - 회귀선
j2 = sns.jointplot(x='fare', y='age', kind='reg', data=titanic)
# 조인트 그래프 - 육각 그래프
j3 = sns.jointplot(x='fare', y='age', kind='hex', data=titanic)
# 조인트 그래프 - 커럴 밀집 그래프
j4 = sns.jointplot(x='fare', y='age', kind='kde', data=titanic)
# 차트 제목 표시
j1.fig.suptitle('titanic fare - scatter', size=15)
j2.fig.suptitle('titanic fare - reg', size=15)
j3.fig.suptitle('titanic fare - hex', size=15)
j4.fig.suptitle('titanic fare - kde', size=15)
- 조건을 사용하여 화면을 그리드로 분할하기
행, 열 방향으로 서로 다른 조건을 적용하여 여러 개의 서브 플롯을 만든다. 그리고 각 서브 플롯에 적용할 그래프 종류를 map() 메소드를 이용하여 그리드 객체에 전달한다.
# 조건에 따라 그리드 나누기
g = sns.FacetGrid(data=titanic, col='who', row='survived')
# 그래프 적용하기
g = g.map(plt.hist, 'age')
- 이변수 데이터의 분포
pairplot() 함수느 인자로 전달되는 데이터프레임의 열을 두 개씩 짝을 지을 수 있는 모든 조함에 대해 표현한다.
# titanic 데이터셋 중에서 분석 데이터 선택하기
titanic_pair = titanic[['age','pclass', 'fare']]
# 조건에 따라 그리드 나누기
g = sns.pairplot(titanic_pair)
3. Folium 라이브러리 - 지도 활용
- 지도 만들기
Folium 라이브러리의 Map() 함수를 이용하면 간단하게 지도 객체를 만들 수 있다.
# 라이브러리 불러오기
import folium
# 서울 지도 만들기
seoul_map = folium.Map(location=[37.55,126.98], zoom_start=12)
# 지도를 HTML 파일로 저장하기
seoul_map.save('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/seoul.html')
- 지도 스타일 적용하기
Map() 함수에 tiles 옵션을 적용하면 지도에 적용하는 스타일을 변경하여 지정이 가능하다
# 라이브러리 불러오기
import folium
# 서울 지도 만들기
seoul_map2 = folium.Map(location=[37.55,126.98], tiles='Stamen Terrain',
zoom_start=12)
seoul_map3 = folium.Map(location=[37.55,126.98], tiles='Stamen Toner',
zoom_start=15)
# 지도를 HTML 파일로 저장하기
seoul_map2.save('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/seoul2.html')
seoul_map3.save('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/seoul3.html')
- 지도에 마커 표시하기
서울 시내 주요 대학교의 위치 데이터를 데이터프레임으로 변환하고, Folium 지도에 위치를 표시
# 라이브러리 불러오기
import pandas as pd
import folium
# 대학교 리스트를 데이터프레임으로 변환
df = pd.read_excel('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/서울지역_대학교_위치.xlsx', engine='openpyxl')
# 서울 지도 만들기
seoul_map = folium.Map(location=[37.55, 126.98],
tiles='Stamen Terrain',
attr='Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under ODbL.',
zoom_start=12)
# 대학교 위치 정보를 Marker로 표시
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.Marker([lat, lng], popup=name).add_to(seoul_map)
# 지도를 HTML 파일로 저장하기
seoul_map.save('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/seoul_colleges.html')folium.Map에서 tiles='Stamen Terrain'을 사용할 때는 attr (attribution) 매개변수를 추가해야 합니다. 이 매개변수는 타일이 어디서 왔는지, 그리고 저작권 정보를 표시하는 데 사용됩니다.
attr 특성 추가안하면 안돌아감!!!
# 원형 마커
Marker() 함수 대신에 CircleMarker() 함수를 사용
# 대학교 위치정보를 CircleMarker로 표시
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.CircleMarker([lat, lng],
radius=10, # 원의 반지름
color='brown', # 원의 둘레 색상
fill=True,
fill_color='coral', # 원을 채우는 색
fill_opacity=0.7, # 투명도
popup=name
).add_to(seoul_map)
- 지도 영역에 단계구분도 표시하기
행정구역과 같이 지도 상의 어떤 경계에 둘러싸인 영역에 색을 칠하거나 음영 등으로 정보를 나타내는 시각화 방법
전달하려는 정보의 값이 커지면 영역에 칠해진 색이나 음영이 정해짐.
Choropleth() 함수 이용
# 라이브러리 불러오기
import pandas as pd
import folium
import json
# 경기도 인구변화 데이터를 불러와서 데이터프레임으로 변환
file_path = 'C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/경기도인구데이터.xlsx'
df = pd.read_excel(file_path, index_col='구분', engine='openpyxl')
df.columns = df.columns.map(str)
# 경기도 시군구 경계 정보를 가진 geo-json 파일 불러오기
geo_path = 'C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/경기도행정구역경계.json'
try:
geo_data = json.load(open(geo_path, encoding='utf-8'))
except:
geo_data = json.load(open(geo_path, encoding='utf-8-sig'))
# 경기도 지도 만들기
g_map = folium.Map(location=[37.5502, 126.982],
tiles='Stamen Terrain',
attr='Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under ODbL.',
zoom_start=9)
# 출력할 연도 선택 (2007 ~ 2017년 중에서 선택)
year = '2017'
# Choropleth 클래스로 단계구분도 표시하기
folium.Choropleth(
geo_data=geo_data, # 지도 경계
data=df[year], # 표시하려는 데이터
columns=[df.index, df[year]], # 열 지정
fill_color='YlOrRd', fill_opacity=0.7, line_opacity=0.3,
threshold_scale=[10000, 100000, 300000, 500000, 700000],
key_on='feature.properties.name',
).add_to(g_map)
# 지도를 HTML 파일로 저장하기
g_map.save('C:/Users/sajog/Downloads/5674-980/pandas-data-analysis-main/part4/data/gyonggi_population_' + year + '.html')마찬가지로 attr 특성 추가안하면 안된다.